第 3 堂課 - LACP 與 bonding/team 及 IPv6 簡易設定
上次更新日期 2022/09/21
如果不是在用戶端很多的情況下,其實頻寬會被塞爆的情況,大多發生在企業內部喔!因為對外其實不會有很大的頻寬使用。 如果有 10G switch 當然是很好,不過以目前入門型 10G switch 就要數個萬的價格,恐怕大家還是會習慣使用 1G switch 吧? 那可能就得要有 LACP 或 bonding 或 team 這種機制來增加單一主機或單一線路的頻寬喔!
學習目標
- 了解 LACP 的應用場景
- 學會多張網卡整併的 bonding 與 team 功能
- 簡易的 IPv6 網路位置理解與在 Linux 系統的設定
- 3.1: 區域網路拓樸與 LACP 的需求
- 3.2: Linux bonding 的頻寬處理
- 3.3: Linux team 的頻寬處理
- 3.4: IPv6 基礎與設定
- 3.5: 課後練習
3.1: 區域網路拓樸與 LACP 的需求
電腦數量不多的時候,透過一部 switch 來連結各個 LAN 裡面的電腦,然後再透過一部 gateway 連結外部網路,大概也就沒啥問題了。 但是,若以學校的電腦教室來說,一間教室 30~60 台電腦,若每個電腦在區網路都向同一部 Server 要資料的時候,你覺得每一部 PC 可以下載的頻寬會是多少? 而 Server 可以提供的最大頻寬又是多少?這兩者有沒有關係呢?當然是有的啊!
- 一般企業/學校在電腦數量龐大的情況下,通常的網路接法
以資傳系為例,我們有兩間電腦教室超過 50 台電腦,那一般的不是很昂貴的 switch 最多也不過是 48 port 而已,此時至少就得要串接兩個 switch 才行! 假設如下圖示的接法:
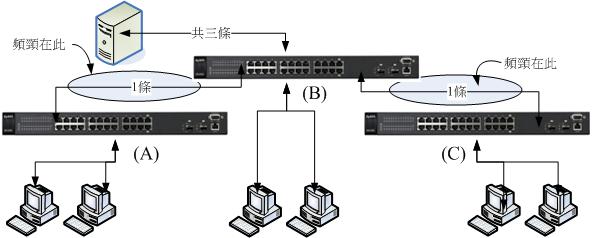
仔細看上圖的結果喔:
- 直接連主幹 switch:
當有三部 PC 直接連上 B 這個 switch 時,這三部 PC 可以獲得完整的伺服器提供的三張網卡總頻寬。 - 非主幹的 switch :
但如果是 A 與 C 區連接的 PC 呢?由於 A 到 B 兩個 switch 僅使用到一個埠口,因此這兩個 switch 之間最大的頻寬當然也只有 1Gbits/s 的量,所以,如果 A 區有三部 PC 要使用伺服器的資源時,你猜猜網路流量的頻頸在哪裡? 想也知道是兩個 switch 間的總流量啊!那怎麼辦?能不能在兩部 switch 之間接上兩條以上的網路線啊?
- 常見的小型企業網路拓樸:
一般企業可能會有架設伺服器的小機房,然後又有員工所用的生產機器,因此習慣上的接法會這樣區分:
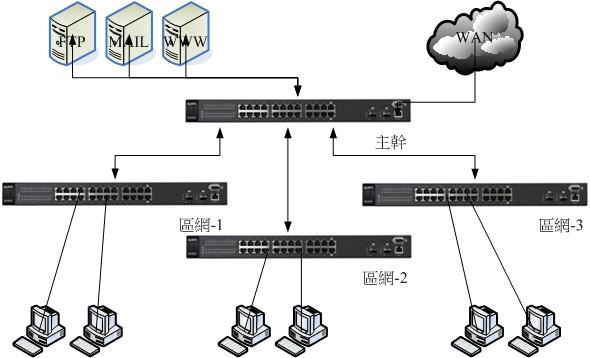
上述的連接方式是比較簡單且單純的:
- 如果你的區網內,每個員工常常有需要連線到 FTP 去下載大型檔案時,那麼這個連線的架構的頻頸將會發生在 FTP server 到 switch 這一段。
- 如果區網-1 的內部網路中,有個特殊的服務被啟動,而區網-2 的員工都得要去存取他時,那麼頻頸就會發生在 switch 到 switch 連接的那個 port 上面囉。
- 單一主機的多個網段服務
例如資傳系的 DRBL 快速復原系統的環境:

缺點是,你得要區分不同的 switch 與 port 以及相關的 DHCP 或 IP 的設定才行!而不是將所有的網路全部串接在一起而已!連接上面要很小心!
- 透過 switch 的 LACP 增加頻寬
如果你的 switch 可以支援 LACP 的功能,那才可以使用底下的連接方式:
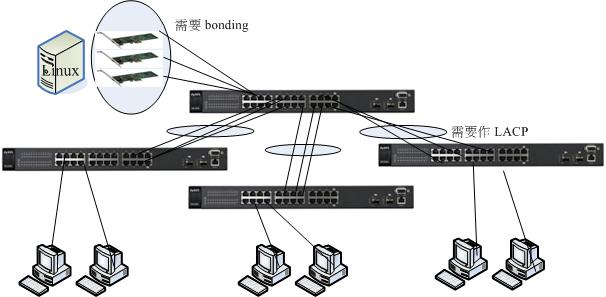
如上圖所示,主控的 (最上方那部) switch 僅直接連接伺服器與 switch 而已,並不接受一般 PC 的連接。至於其他三部 switch 則是每部連接 20 個 PC 終端設備。 因為使用 24 port switch,所以這三部 switch 總共會花費 20+3 個埠口,就剩下一個備用的囉。其他共用設備 (印表機、伺服器等) 就都接在主控 switch 上頭, 如此一來,一般的網際網路連線,就只會經過主控 switch 與該 PC 連接的 switch,其實是有擴大頻寬的功能的。
- 觀察一下本教室的網路連接方式,進一步繪製出網路連接的拓樸圖示。
- 就你的觀察,全 10G switch 對於 PC 與 PC 之間,還有 PC 與 server 之間有沒有很大幅度的效益?為什麼? 請就頻寬、傳輸速度、PC/server可以負荷的最大讀寫效能做解釋。
事實上,骨幹才需要全 10G switch,其他的辦公室內,大概 2port 10G + N port 1G 的 switch 規劃,可能會是比較好又便宜的解決方案。
要注意的是,兩個 switch 不可以在沒有設定 LACP 或其他相關協定時,使用兩條以上 (含) 的網路線連接~ 如果你用了兩條以上的網路線串連兩部 switch, 這時就會產生 switch 內部的廣播風暴,好一點的 switch 會自動的關閉被你連接的那幾個埠口 (那幾個埠口不能使用了),差一點或者是沒有設定防堵機制的, switch 可能會熱當或者是造成連接到該 switch 的所有設備無法連線的問題喔!要注意!要注意!很嚴重!很嚴重!
- 那,什麼是 LACP
LACP 的全名是 Link Aggregation Control Protocol,中文翻譯為『鏈路聚合控制協定』,這個通訊協定可以在 switch 對 switch 之間,或 switch 對 PC 之間有連線的需求時,可連接多條實體網路線,以達到網路連線容錯以及增加兩者間頻寬的目的。
這個 LACP 協定最初發展的目的就有兩個,一個是由於有多條連線,因此連線就具有容錯功能,可以在某條連線失敗時, 兩者間的連線依舊可以透過其他存在的連線來達成。另一個就是在增加整體的網路流量傳輸率(throughput)。
那麼 LACP 實際上在 switch 的連線是如何進行資料傳送的呢?其實所有的資料都會被分散在實體的 switch 間的連線中,另外,我們知道 switch,尤其是第二層的 switch 主要是針對網卡卡號 (MAC) 來進行資料的傳送,為了不要讓 switch 一直在埠口間切換同一個 MAC,因此, 同一部主機所發出的連續訊框 (frame), 基本上都會透過同一個實體網路線來傳送,而不是交替在不同的網路線間傳送。
舉例來說,如果有兩條對接的線,在兩邊的 switch 各有兩部主機,並且分別對另一台 switch 的主機連線。理論上,兩兩 PC 連線會透過不同的兩條實體線路連接, 所以總頻寬就可以增加一倍了!當然,這是最佳的情況啦!
3.2: Linux bonding 的頻寬處理
前一個小節的許多圖示當中,你會發現有時候 Linux Server 會有多張網卡的埠口~這啥鬼?這些埠口是分別有各別的 IP 網路參數設定? 還是共用 IP 參數呢?個別的網路參數還好說 (前一章我們已經設定過內/外網卡了),那如果是共用 IP 網路參數呢?也就是說, 兩張以上的網卡共用一個 IP 呢?可行嗎?可以的!這就是類似 bonding 的功能!
- 什麼是 bonding
早期由於乙太網路卡的速度還不夠快,那如果妳的伺服器需要比較大的頻寬使用時,就得要購買更昂貴的設備才行。 那為什麼不能將幾張網卡合併成為一張來擴大頻寬呢?此外,對於重要的服務來說,網路是不能中斷的!所以,能不能使用兩條以上的線路連接到我的伺服器呢? 因此,(1)合併網路卡的頻寬與 (2)讓網路具有容錯能力 (fault tolerance) 就成了 Linux bonding 最主要的考量了! 目前 Linux bonding 功能已經加入核心,所以妳只要啟動它即可!不需要額外安裝其他軟體呦!
- Bonding 的模式與功能:
bonding 根據當初設計理念的不同,有許多常用的模式可以參考:
- 模式 0,循環負載平衡合併頻寬 (Round-robin, balance-rr):
Linux bonding 會將要發送的封包循序的從任何可用的網卡上面循環發送,因為是循環發送的,所以每張網卡就能夠被充分利用~ 不過,就鳥哥的經驗來看,這種模式的負載平衡方面似乎沒有想像中的好!所以鳥哥不建議使用。 - 模式 1,自動備援模式 (Active-backup):
假設有三個網路卡做成這種 bonding 模式的話,那麼永遠都只有一個網路卡會運作,我們稱之為主要網卡 (primary)!除非這個主要網卡連線失敗了, 另一張網卡 (slave) 才會扶正而成為下一個主要網卡,並持續提供服務。這種模式並不會合併頻寬,只會用在連線的容錯而已。 - 模式 4,LACP 鏈路聚合模式 (IEEE 802.3ad Dynamic link aggregation):
這種模式算是業界的標準支援吧!妳的 bonding 網卡啟動在這種模式下,然後讓串接到這些網卡的 switch 埠口設定好 LACP 群組, 這樣就能夠達成與 LACP 相同的頻寬倍增功能!這種模式得要有支援網管且提供 LACP 設定的 switch 才行!這種模式可以同時提供合併頻寬與網路容錯! - 模式 5,自動調整傳輸負載平衡 (Adaptive transmit load balancing, balance-tlb):
在傳送方面,這種模式會將封包分散在各個可用的 bonding 網卡上送出,因此傳送才能夠達到合併頻寬。不過在接收封包時, 由於考慮到 switch 的 MAC 記憶能力,因此僅有一個網卡的 MAC 會被紀錄於 switch 上頭,簡單的說,就是僅有一張網卡會用於接收! 除非該接收網卡掛點, 否則其他網卡不會被用在接收上。這種模式也算挺適合用在『主要在發送資料給用戶端的 Server 』上, 如果 server 也要負責大量資料的接收,恐怕就不是這麼適合了。 - 模式 6,自動調整全負載平衡 (Adaptive load balancing, balance-alb):
這個模式包括了模式 5,除了傳送可以合併頻寬之外,連接收也可以合併頻寬了。當伺服器要傳資料出去給用戶端時,bonding 模組會主動的攔截封包, 並透過 ARP 協商機制 (ARP 就是透過 IP 去找出 MAC 的通訊協定),將不同的網卡要送出到同一個用戶端的封包,都改寫成單一一個固定的發送端 MAC 位址, 如此一來,發送有合併頻寬的功能了,但接收卻還是只有一個 MAC 而已對吧?那怎麼說接收有合併頻寬的負載平衡機制呢?
原因是這樣的:當有資料封包要送出到多個不同的用戶端時,此模式的 bonding 模組就會透過 ARP 協商機制,找出 bonding 管理的比較閒置的網卡 MAC 分配給下個用戶端,如此一來,不同的用戶端回傳給伺服器的資料,就可以透過不同的網卡來接收,就能達到接收也合併頻寬的功能了。
這個模式不需要特別的 switch 支援,而且設定簡單,可以在接收、傳送都達成合併頻寬的能力,且也具有基本的網路容錯功能, 是目前鳥哥最愛使用的 bonding 模式啦!
- Linux bonding 處理
你得要先知道為什麼要做 bonding 呢?可能的原因有兩個:
- 為了讓網路連線有備援,因此斷了一條網路的時候,另一條網卡會主動接管
- 為了增加頻寬
如果是為了第一點,那使用 bonding 模式 1 (Active-backup) 的功能最好!如果是為了第二點,那你得要注意,就是你 server 提供的資料速度要比兩張網卡更快, 所以你的硬碟不能太慢 (當然,如果傳輸的資料是在記憶體,那就無關硬碟),而且,同一個用戶端與 server 之間的連線,最多只能有一條網路線的頻寬使用, 因此你的 client 端如果也用兩張網卡想要綁定到 server,其實是無法增加頻寬的喔!這點要先說明。
所以,如果是為了增加頻寬,那你就應該要有這樣的想法:
- 你的 Server 總體讀/寫速度要高於所有網卡的頻寬總和才好
- 你的網卡所連接的 switch 總背板頻寬 (bandwidth) 要能夠負荷 bonding 的最高流量
- 用戶端的數量要比網卡數還要多才合理
- 事先工作:先了解網卡的狀態
你要 bonding 的網卡應該要連接到同一個 switch 上面,而且未來會創造一個新的 bonding 網卡,所以你的實體網卡上面的設定應該要先去除。 因此,先讓我們把 ens7, ens8 這兩個連線去掉
[root@localhost ~]# nmcli connection delete ens7 [root@localhost ~]# nmcli connection delete ens8
- 建立 bonding 網卡:
再來建立 bonding 網卡就使用 nmcli 來建立即可~我們假設這張網卡的連線名稱為 bond0 (con-name bond0),且實際網卡名稱也是 bond0 (ifname bond0), 使用的類型為 bond (type bond),然後使用的參數為模式 6 或稱為 balance-alb ,大約 100 ms 檢查一次網路,所以整體的設定會是這樣:
[root@localhost ~]# nmcli connection add con-name bond0 ifname bond0 \ > type bond bond.options "miimon=100,mode=6" [root@localhost ~]# nmcli connection show NAME UUID TYPE DEVICE bond0 fb901bbd-bb61-4080-9c50-97db5649570b bond bond0 ens3 0af5a13a-792e-4b62-a671-2371e183b31b 802-3-ethernet ens3
這樣就建立了 bond0 這張網路卡。問題是,還沒有任何一個附掛的實體網卡給 bond0 使用~這時就得要這樣做:
- 建立支援 bonding 的實體網卡,透過 bond-slave 類型:
附掛在 bonding 底下的實體網卡使用的類型為 bond-save,而主要的參數就是設定主人 (master) 為 bond0 即可!
[root@localhost ~]# nmcli connection add con-name ens7 ifname ens7 type bond-slave \ > master bond0 [root@localhost ~]# nmcli connection add con-name ens8 ifname ens8 type bond-slave \ > master bond0 [root@localhost ~]# nmcli connection show NAME UUID TYPE DEVICE bond0 fb901bbd-bb61-4080-9c50-97db5649570b bond bond0 ens3 0af5a13a-792e-4b62-a671-2371e183b31b 802-3-ethernet ens3 ens7 48fc4ea4-6e19-4f4f-b2d8-00cef479ee29 802-3-ethernet ens7 ens8 25ef25a4-349d-458f-9071-c439843f8473 802-3-ethernet ens8 [root@localhost ~]# ip addr show 3: ens7: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast master bond0 state UP qlen 1000 link/ether 52:54:00:f4:bd:20 brd ff:ff:ff:ff:ff:ff 4: ens8: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast master bond0 state UP qlen 1000 link/ether 52:54:00:34:ab:27 brd ff:ff:ff:ff:ff:ff 9: bond0: <BROADCAST,MULTICAST,MASTER,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP qlen 1000 link/ether 52:54:00:f4:bd:20 brd ff:ff:ff:ff:ff:ff inet6 fe80::3db0:ba24:9d55:6dd6/64 scope link valid_lft forever preferred_lft forever [root@localhost ~]# nmcli connection up bond0 [root@localhost ~]# nmcli connection up ens7 [root@localhost ~]# nmcli connection up ens8
- 最後觀察目前的使用情況:
直接查看記憶體內的參數即可了解目前的 bonding 狀態!
[root@localhost ~]# cat /proc/net/bonding/bond0 Ethernet Channel Bonding Driver: v3.7.1 (April 27, 2011) Bonding Mode: adaptive load balancing Primary Slave: None Currently Active Slave: ens7 MII Status: up MII Polling Interval (ms): 100 Up Delay (ms): 0 Down Delay (ms): 0 Slave Interface: ens7 MII Status: up Speed: Unknown Duplex: Unknown Link Failure Count: 0 Permanent HW addr: 52:54:00:f4:bd:20 Slave queue ID: 0 Slave Interface: ens8 MII Status: up Speed: Unknown Duplex: Unknown Link Failure Count: 0 Permanent HW addr: 52:54:00:34:ab:27 Slave queue ID: 0
- 最後,修改成正確的 IP 參數即可!
[root@localhost ~]# nmcli connection modify bond0 ipv4.method manual \ > ipv4.addresses 10.255.200.254/24 [root@localhost ~]# nmcli connection up bond0 [root@localhost ~]# ifconfig bond0 bond0: flags=5187<UP,BROADCAST,RUNNING,MASTER,MULTICAST> mtu 1500 inet 10.255.200.254 netmask 255.255.255.0 broadcast 10.255.200.255 inet6 fe80::3db0:ba24:9d55:6dd6 prefixlen 64 scopeid 0x20<link> ether 52:54:00:f4:bd:20 txqueuelen 1000 (Ethernet) RX packets 20 bytes 2820 (2.7 KiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 457 bytes 29100 (28.4 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
- 啟動你的用戶端電腦,依據前一章設定好的網路狀態 (10.255.*.1/24) 後,檢查看看能不能 ping 到你的 server 10.255.*.254 那個 IP 呢?
- 在 Server 與 Client 端,分別使用 arp -n 查詢 IP 的 mac 對應,說明目前生效的 bond0 使用那一個網卡?
- 在 client 端一直 ping server_IP 不要停,在 server 端關閉 ens7 ,看看 active 的網卡會變什麼?且 client 網路會不會中斷?
透過上面的練習,你會知道 bonding 的好處喔!
3.3: Linux team 的頻寬處理
Linux bonding 幾乎完全是 Linux 核心預設的支援,但許多 distribution 比較傾向於使用更多使用者空間的 team 這個服務!其實 team 跟 bonding 幾乎一模一樣! 最大的差別就是一個在核心,一個有更多的使用者控制功能。但是要使用 team 就得要有 teamd 這個服務才行!不過不用擔心, RockyLinux 預設都有安裝了!為了確認,我們還是來查一查好了:
[root@localhost ~]# which teamd /usr/bin/teamd [root@localhost ~]# find /usr/lib/systemd/ -type f | grep team /usr/lib/systemd/system/teamd@.service
因為 team 要做的跟 bonding 其實是一樣的!因此,如果要實做 team 的話,請將 bonding 取消吧!所以,事前工作就是刪除 bonding 囉!
[root@localhost ~]# nmcli connection delete ens7 [root@localhost ~]# nmcli connection delete ens8 [root@localhost ~]# nmcli connection delete bond0
再來就是準備要建立一個 team0 的網卡,也是很簡單!不過要注意的是, team 的模式主要有底下幾種:
- activebackup (就是 bonding 的 mode 1)
- roundrobin (就是 bonding 的 mode 0)
- loadbalance (就是 bonding 的 mode 6)
- lacp (就是 bonding 的 mode 4)
不同於 bonding 的設定只要指定模式就好, team 的設定內容比較複雜,很多關鍵字要記憶!如果要建立一個自動備援的 team ,就得這麼做:
'{"runner":{"name":"activebackup"}}'
現在讓我們來實做一個 team0 的連線,網卡名稱為 team0,而設定為 activebackup (不是 loadbalance 喔!)
[root@localhost ~]# nmcli connection add con-name team0 ifname team0 type team \ > config '{"runner":{"name":"activebackup"}}' [root@localhost ~]# nmcli connection show team0 connection.id: team0 connection.interface-name: team0 connection.type: team team.config: {"runner":{"name":"activebackup"}} [root@localhost ~]# nmcli connection add con-name ens7 ifname ens7 \ > type team-slave master team0 [root@localhost ~]# nmcli connection add con-name ens8 ifname ens8 \ > type team-slave master team0
修改網路參數吧,因為 team0 要有網路參數後,才有辦法順利啟動。如果使用 dhcp 的話,team0 很可能會無法啟用, 因為我們的內網並沒有 DHCP 的伺服器存在之故。
[root@localhost ~]# nmcli connection modify team0 ipv4.method manual \ > ipv4.addresses 10.255.200.254/24 [root@localhost ~]# nmcli connection up team0 [root@localhost ~]# nmcli connection up ens7 [root@localhost ~]# nmcli connection up ens8 [root@localhost ~]# ifconfig team0 team0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 10.255.200.254 netmask 255.255.255.0 broadcast 10.255.200.255 inet6 fe80::a917:23db:27cd:3aa1 prefixlen 64 scopeid 0x20<link> inet6 fe80::5362:bce8:3ba:fed7 prefixlen 64 scopeid 0x20<link> inet6 fe80::d75c:9763:f9f5:b3ed prefixlen 64 scopeid 0x20<link> ether 52:54:00:f4:bd:20 txqueuelen 1000 (Ethernet) RX packets 22 bytes 2732 (2.6 KiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 22 bytes 3040 (2.9 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
接下來查看一下 team 是否正確的運作中!這時就得要使用 teamd 提供的管理功能了!
[root@localhost ~]# teamdctl team0 state setup: runner: activebackup ports: ens7 link watches: link summary: up instance[link_watch_0]: name: ethtool link: up down count: 0 ens8 link watches: link summary: up instance[link_watch_0]: name: ethtool link: up down count: 0 runner: active port: ens7
- 啟動你的用戶端電腦,依據前一章設定好的網路狀態 (10.255.*.1/24) 後,檢查看看能不能 ping 到你的 server 10.255.*.254 那個 IP 呢?
- 在 Server 與 Client 端,分別使用 arp -n 查詢 IP 的 mac 對應,說明目前生效的 team0 使用那一個網卡?
- 在 client 端一直 ping server_IP 不要停,在 server 端關閉 ens7 ,看看 active 的網卡會變什麼?且 client 網路會不會中斷?
鳥哥是覺得兩個功能效果都差不多,就看你個人的喜好而定了。目前 RockyLinux 預設建議使用 team 就是了!參考看看。 另外,經過測試的結果,team0 在 loadbalance 底下要支援 IPv6 的設定比較麻煩,所以如果你的 team0 未來會加上 IPv6 的 IP 位址時,就要改成 activebackup 比較好設定!
- 防火牆的暫時處理
因為我們改了網路的配置,變成 server 使用了 team0 啦!界面也改變了!所以,前一章暫時使用的界面 (ens7) 就得要改成 team0 才行! 因為對外的 ens3 沒變,所以,修改信任網域即可:
# firewall-cmd --permanent --zone=trusted --change-interface=team0 # firewall-cmd --reload
所以說,用戶端只要網路設定正確就好,所有的 IP 分享功能,都在 server 上面完成,與用戶端無關!
3.4: IPv6 基礎與設定
IPv4 的網路位址已經發放完畢了,目前新興國家或新的 ISP 若想要取得 IPv4 的話,就只能向其他已經申請的人購買~不過應該還是不夠用的! 因為現在連手機等行動裝置,還有 IOT 的偵測器與收集器都需要用到網際網路,這也都需要 IP 的!所以,沒有新的 IP 來源,那就慘了! 因此,IPv6 就這樣產生囉!
IPv6 跟 IPv4 一樣都在網路層 (layer 3),使用的 IP 封包也差不多,只是表頭資料與相關功能比較不同。相關功能這裡就不說明, 要強調的是 IPv6 使用了 128bits 來作為 IP 位址使用~也就是說 IPv4 用 32 個 0 與 1 排列來展示位址,而 IPv6 用了 128 個 0 與 1 排列來展示位址... 底下沒辦法直接寫下來,實在太長了!
為了簡化位址長度, IPv4 是轉 2 進位為 10 進位,而 IPv6 則是轉 2 進位成為 16 進位 (2 的 4 次方),因此 128/4 = 32 個 16 進位的數字! 所謂的 16 進位指的是 0, 1 ... 9, a, b, c, d, e, f ,其中 f 代表的就是 16 的意思,那每 4 個 16 進位的數字分別做一個區隔, 因此舊有 32/4 = 8 組 16 進位的數值,最小與最大就分別是:
- 0000:0000:0000:0000:0000:0000:0000:0000
- FFFF:FFFF:FFFF:FFFF:FFFF:FFFF:FFFF:FFFF
- IPv6 的 IP 位址簡化表示法:
如上所示,雖然已經經過了一些簡化,而不是使用 128 個 0 與 1 的表示,同時將 IPv4 的 10 進位改為 16 進位,理論上確實少很多數值了, 不過,總數 32 個 16 進位的數值,還是稍嫌長了些~因此,IPv6 的 IP 位址允許做一些簡化的寫法!亦即:
- 在同一個冒號之間的數值,若為連續的 0 ,則只填一個 0 即可
- 在同一個冒號區間的數值,左邊高位元若為連續的0,則可以簡化略過不寫
- 連續(含)一個以上的 :0000: 時,可以使用 :: 來取代,但只能保留一組 :: 的存在。
如下所示,第一行為標準的 IPv6 的 IP 位址寫法,第二行則符合上述第 2 點,連續的 0 可以簡化,第三行則符合上述的第 3 點,超過一個以上的 :0000: 時, 可以使用 :: 來取代,但是只能保留一組,所以第三行右側的 :0:0 就不能繼續簡化了 (通常保留左側高位的數值)
- FE80:1234:5678:0000:0000:0010:0000:0000
- FE80:1234:5678:0:0:10:0:0
- FE80:1234:5678::10:0:0
- IPv6 的子網路遮罩 (Netmask)
就跟 IPv4 的 IP address 一樣具有區網的 netmask IP,IPv4 同樣也有自己的區網所需要指定的 Netmask IP,只是...這個 IPv6 的 netmask 就沒道理還要用 IP 吧? 呵呵!當然是直接使用 bit 來展示了!一般來說,IPv6 的 Netmask 通常使用了 64bit 作為區域網路的劃分,不過就如 IPv4 的無等級 IP (CIDR) 一樣, 你當然也能夠指定自己的 Netmask IP 囉。由於 IPv6 是以 16bit 為一個 IP 位址區段分隔,因此 netmask 也通常就是 16 的倍數,底下以 2001:0db8 這個網段來說明:
- Netmask 為 32 bit 時:
- Network IP: 2001:0db8:0000:0000:0000:0000:0000:0000
- 可以簡化為: 2001:db8::
- Broadcast IP: 2001:0db8:ffff:ffff:ffff:ffff:ffff:ffff
- 網域表示方式:2001:db8::/32
- Network IP: 2001:0db8:0000:0000:0000:0000:0000:0000
- Netmask 為 64 bit 時:
- Network IP: 2001:0db8:1234:5678:0000:0000:0000:0000
- 可以簡化為: 2001:db8:1234:5678::
- Broadcast IP: 2001:0db8:1234:5678:ffff:ffff:ffff:ffff
- 網域表示方式:2001:db8:1234:5678::/64
- Network IP: 2001:0db8:1234:5678:0000:0000:0000:0000
- 只用於區網且只與網卡卡號有關的 Link Local Address 的 IPv6 位址
為了簡化區域網路內部的 IPv6 之 IP 位址設定,因此 IPv6 規劃的時候,有提出一個明於區域網路連結位址 (Link Local Address) 的 IPv6 位址設定方式! 其實很簡單,就是:
- 提供 fe80::/10 的區段給 LAN 使用
- 且最後的 64 位元 (最後 4 組位址數值) 使用網卡卡號來計算
- 同時能使用的區網為 64bit 的設計
因此最終會有 fe80::/64 這一段的區網來使用喔!
[root@localhost ~]# ip addr show ens3 2: ens3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 52:54:00:99:57:99 brd ff:ff:ff:ff:ff:ff inet 192.168.254.200/24 brd 192.168.254.255 scope global ens3 valid_lft forever preferred_lft forever inet6 fe80::714f:d0c7:d7a0:773b/64 scope link valid_lft forever preferred_lft forever [root@localhost ~]# ip addr show team0 7: team0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP qlen 1000 link/ether 52:54:00:37:60:6e brd ff:ff:ff:ff:ff:ff inet 10.255.200.254/24 brd 10.255.200.255 scope global noprefixroute team0 valid_lft forever preferred_lft forever inet6 fe80::21e0:66cf:2134:7703/64 scope link noprefixroute valid_lft forever preferred_lft forever雖然 team0 的 IPv6 位址怪怪的,先不理他,我們來嘗試 ping 一下自己的 IPv6 ens3 的位址看看。 這個 ipv6 的 link-local address 很怪異,結尾需要加上網卡的名稱才行!
[root@localhost ~]# ping6 fe80::714f:d0c7:d7a0:773b%ens3 PING fe80::714f:d0c7:d7a0:773b(fe80::714f:d0c7:d7a0:773b) 56 data bytes 64 bytes from fe80::714f:d0c7:d7a0:773b%ens3: icmp_seq=1 ttl=64 time=0.099 ms 64 bytes from fe80::714f:d0c7:d7a0:773b%ens3: icmp_seq=2 ttl=64 time=0.034 ms 64 bytes from fe80::714f:d0c7:d7a0:773b%ens3: icmp_seq=3 ttl=64 time=0.075 ms ^C --- fe80::714f:d0c7:d7a0:773b ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2000ms rtt min/avg/max/mdev = 0.034/0.069/0.099/0.027 ms要使用 IPv6 的位址時,使用的不是 ping 而是 ping6 喔!你也會發現這是內部網卡自己的功能,所以 IP 的顯示最終都會有網卡名稱存在! 這種網路不能夠跨路由,只能在區網裡面簡單的進行快速 IPv6 的封包傳送!
所以,你會看到所有自動產生的 IPv6 的 IP 位址都是 fe80 開頭的!這是由作業系統根據網卡卡號自動計算產生的喔! 再說一次,不能夠直接對外連網,只能在區域網路內部互相連結而已喔!
- IPv6 的 private IP (Unique Local Address) 與 public IP (Global Unicast Address)
與 IPv4 的 private IP 類似,IPv6 也提供一段的 IP 來給區網使用,使用的區段為 FC00::/7,亦即開頭為 FC00:: ~ FDFF:: 之間的 IP 段落。 目前較常使用 FD00::/8 這一網段。
至於 public IP 則使用 2000::/3 (2000:00 ~ 3FFF::) 這一大段,與 IPv4 的 public IP 一樣,你的 IPv6 位址得要從你的 ISP 處取得, 才能夠順利的以 IPv6 的 IP 位址連上 Internet 的。那麼有沒有那一段 Public IP 可作為測試的區段呢? 有的,那就是 2001:0db8::/32 這一大段 IP 位址可以提供給測試範本 (example) 使用,亦即是,你可以使用這一段 IP 位址來測試你的 IPv6 網路囉! 那怎麼設定呢?一樣啊!使用 nmcli 來設定 ipv6.addresses 即可!
讓我們來實際測試一下,在外部網路 (ens3 這張網卡) 請使用 2001:0db8:1000::XX/64,其中 XX 就直接是你的 IP 尾數好了!反正都是數字, 符合 16 位元的設計即可!不用轉成 16 進位了!
[root@localhost ~]# nmcli connection show ens3 | grep ipv6 ipv6.method: auto ipv6.dns: -- ipv6.dns-search: -- ipv6.dns-options: -- ipv6.dns-priority: 0 ipv6.addresses: -- ipv6.gateway: -- ....(預設什麼都沒有).... [root@localhost ~]# nmcli connection modify ens3 ipv6.method manual \ > ipv6.addresses 2001:0db8:1000::200/64 [root@localhost ~]# nmcli connection up ens3 [root@localhost ~]# nmcli connection show ens3 | grep ipv6 ipv6.method: manual ipv6.dns: -- ipv6.dns-search: -- ipv6.dns-options: -- ipv6.dns-priority: 0 ipv6.addresses: 2001:db8:1000::200/64 [root@localhost ~]# nmcli connection show ens3 ....前面的先省略不看.... IP4.ADDRESS[1]: 192.168.254.200/24 IP4.GATEWAY: 192.168.254.254 IP4.DNS[1]: 120.114.100.1 IP4.DNS[2]: 168.95.1.1 IP6.ADDRESS[1]: fe80::a14c:196e:5480:6621/64 IP6.ADDRESS[2]: 2001:db8:1000::200/64 IP6.GATEWAY: [root@localhost ~]# ping -6 2001:db8:1000::200 64 bytes from 2001:db8:1000::200: icmp_seq=1 ttl=64 time=0.077 ms 64 bytes from 2001:db8:1000::200: icmp_seq=2 ttl=64 time=0.047 ms 64 bytes from 2001:db8:1000::200: icmp_seq=3 ttl=64 time=0.027 ms ^C --- 2001:db8:1000::c8 ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 1999ms rtt min/avg/max/mdev = 0.024/0.041/0.057/0.013 ms
最後用 ping6 來檢查看看對不對喔!
- 在 server 內部網路 (team0 這張網卡) 請使用 2001:0db8:2000:XX::254/64
- 在 client 端的 ens3 上面,請用 2001:0db8:2000:XX::1/64 來設定網路。
最終使用 ping6 serverIP, ping6 clientIP 來查詢兩者是否能夠互通就 OK 了!最後,一般來說,我們要寫 IPv4 的 socket 使用 10.255.200.254:80 這樣的模式, 那麼 IPv6 怎麼寫呢?就得要寫成 [2001:0db8:2000:XX::254]:80 囉!亦即 IPv6 的 IP 位址加上中括號來區隔 port 號!這樣理解否?
3.5: 課後練習
- (50%)實作題:啟動 Server 作業硬碟 - unit3
- 網路參數的設定,請依據底下的方式來設定好你的網路環境:
- 建立 ens3 為外部的連線網卡 (相同的連線界面名稱),使用 ethernet 類型,且:
- IPv4 的 IP位址: 172.18.255.*/24 ,其中 * 為老師規定的 IP 尾數
- gateway 為 172.18.255.254
- DNS 為 172.16.200.254 以及 168.95.1.1
- 使用 teamd 的機制建立內部區域網路的備援功能:
- team 的界面使用 team0 卡號,且連線名稱請命名為 team0
- team 使用 activebackup 備援功能,不要使用 loadbalance
- team 的實體網卡 (team slave) 請使用 ens7 及 ens8 ,且其連線名稱名稱亦請命名為 ens7, ens8
- team0 網路參數為: 172.19.*.254/24,不需要 gateway
- 主機名稱指定為: server*.example.dic
- 最終你的主機名稱與 IP 的對應為:
server*.example.dic 172.18.255.* 別名為 server* server254.example.dic 172.18.255.254 別名為 server254 server.lan*.example.dic 172.19.*.254 別名為 server client.lan*.example.dic 172.19.*.1 別名為 client
- 建立 ens3 為外部的連線網卡 (相同的連線界面名稱),使用 ethernet 類型,且:
- 基本的伺服器作業系統設定行為:
- 依據底下的說明,選擇距離我們最近的成大網站來作為 yum server 的來源:
成大 ccns 網站: https://mirror.ccns.ncku.edu.tw/howto/#rocky-linux
請記得修改過設定檔,應該要將清單清除 (yum clean all) 較佳。 - 安裝相關的軟體,至少須安裝 vim-enhanced, bash-completion, net-tools, bind-utils, kernel
- 全系統自動升級,且每天凌晨 3 點也會自動升級一次。(請寫入 /etc/crontab 為主)
- 將 SELinux 修改成為 Enforcing 模式,且未來每次開機都自動為 Enforcing 才行
- 依據底下的說明,選擇距離我們最近的成大網站來作為 yum server 的來源:
- IPv6 的設定:
- 在你的 team0 網卡上面設定 IPv6 的位址為: 2001:db8:3000:XX::ff/64,其中 XX 為你的 IP 尾數,直接輸入 10 進位數字,不用轉為 16 進位
- 你的 IPv6 主機名稱與 IP 的對應最終會成為:
server6.lan*.example.dic 2001:db8:3000:*::ff 別名為 server6 client6.lan*.example.dic 2001:db8:3000:*::1 別名為 client6
亦即當你 ping6 server6 或 ping6 client6 時,就會主動連接到正確的 IPv6 位址去!
- 預先設定防火牆系統 (這題不計分,為了用戶端而處理的!)
# firewall-cmd --permanent --zone=external --change-interface=ens3 # firewall-cmd --permanent --zone=trusted --change-interface=team0 # firewall-cmd --reload
- 網路參數的設定,請依據底下的方式來設定好你的網路環境:
- (20%)實作題:啟動 client 作業硬碟
- 網路參數的設定,請依據底下的方式來設定好:
- 建立 ens3 的連線網卡 (相同的連線界面名稱),使用 ethernet 類型,且:
- IPv4 的 IP位址: 172.19.*.1/24 ,其中 * 為老師規定的 IP 尾數
- gateway 為 172.19.*.254
- DNS 為 172.16.200.254 以及 168.95.1.1
- 主機名稱指定為: client.lan*.example.dic
- 最終你的主機名稱與 IP 的對應為:
server*.example.dic 172.18.255.* 別名為 server* server254.example.dic 172.18.255.254 別名為 server254 server.lan*.example.dic 172.19.*.254 別名為 server client.lan*.example.dic 172.19.*.1 別名為 client
- 建立 ens3 的連線網卡 (相同的連線界面名稱),使用 ethernet 類型,且:
- IPv6 的設定:
- 在你的 ens3 網卡上面設定 IPv6 的位址為: 2001:db8:3000:XX::1/64,其中 XX 為你的 IP 尾數
- 你的 IPv6 主機名稱與 IP 的對應最終會成為:
server6.lan*.example.dic 2001:db8:3000:*::ff 別名為 server6 client6.lan*.example.dic 2001:db8:3000:*::1 別名為 client6
亦即當你 ping6 server6 或 ping6 client6 時,就會主動連接到正確的 IPv6 位址去!
- 網路參數的設定,請依據底下的方式來設定好:
- (30%)簡易問答題:
從具有 GUI 及中文的用戶端 Linux ,使用『 ssh root@172.19.*.254 』登入你的 Server ,之後建立 /root/ans.txt 的檔案,並將底下各題目的答案寫入你 server 當中!
- 當同一條網路線的兩個 RJ-45 水晶頭同時插入一個 switch 時,會發生什麼問題?
- 在有簡單網管功能的 switch 中,哪一個設定的啟動,可以在發生上述問題的時候,可以提供保護 (會將該 port drop 掉, 請上網 google 找關鍵字 "switch broadcast storm protection" 所提供的資訊)
- 承上,在一般固定 IP 的手動設定環境中,上述功能啟動是比較好的。但如果在電腦教室的自動取得 IP 環境 (dhcp) 下, 該功能可能會造成什麼後果?
- 為了增加兩部 switch 之間的溝通頻寬,可不可以直接在兩個 switch 上面,選用兩個 port 互接兩條網路線即可?如果可以就寫可以,如果不可以, 那該如何處理?
- 計算出 192.168.10.100/27 的 Network IP, broadcast IP, Netmask IP 以及可用 IP 範圍
- 本課程中提到的,如果要讓 server 增加頻寬,可以使用那兩種機制來處理?
- 說明 bonding 的模式 1 及模式 6 最主要的差別在哪裡?
- 要了解 bonding 有沒有成功執行,以及 bonding 的網卡用的是哪幾個實際網卡,可以觀察那一個檔案?假設你現有的 bonding 網卡為 bond1 時。
- 如果你有兩個 client ,分別為 PC1 及 PC2,這兩個 client 都有設定 bonding,且都使用 mode6 ,同時均有兩張網卡。 你有一個 server 為 serverA,ServerA 有四張網卡,同時也設定了 bonding,同時也使用了 mode6,且這共 8 張網卡均安插在同一個交換器上面。 請問, PC1 對 ServerA,以及 PC2 對 ServerA 的上傳下載頻寬,最大各為多少?
- team 的那兩個模式分別對應 bonding 的 mode1 與 mode6 呢?
- 請 man teamd.conf ,寫下 teamd 所支援的所有模式有那幾個?
- IPv6 與 IPv4 在 IP 位址上,個別提供多少位元來記載位址?
- IPv6 的 IP 位址預設以冒號 (:) 隔開,其位址共有幾個間隔?每個間隔佔用多少位元?
- 那一個 IPv6 的網段預設是提供給內部區網使用的,且該網段是不能跨路由的。
- IPv6 提供那一個網段來作為 private IP?
- IPv6 提供那一個網段來作為範例用途 (example) ?
- 有一個 IP 網段為: 2001:0db8:0300:0000:0000:0001:0000:0000,請問這個 IP 可以怎麼做簡化?
- 上傳成績
- 請將 Server/Client 的硬碟通通啟動,並且確認兩者間的連線沒有問題;
- 在 Server 硬碟上面登入,然後用 root 的身份執行 vbird_server_check_unit ,並依據提示資料填寫你的學號與 IP 尾數
- 該程式會偵測你的系統,並且通知你哪個部份可能有問題,你需要持續觀察或者重新處理的部份會交代妥當。
- 若一切沒問題,螢幕就會出現如下的字樣,然後你就能夠使用 links 去檢查你的檔案是否有順利的上傳了!
- Please use links http://172.18.255.250/upload/unit03 to check your filename
- 2017/09/20:第一次以 CentOS 7 完成的版本
- 2020/09/29:修改為 CentOS 8 的版本,且主要以 ens3, ens7, ens8 取代 eth0, eth1, eth2 了!
- 2020/10/07:將作業的資料修訂一下,收集成績的腳本原來一直是錯的...已經訂正了!
- 2022/09/21:大致將資料移轉到 RockyLinux 9 上面,ping6 可以用 ping -6 來處理!其實 ping 已經會自動判斷了!